CentOS7 搭建 Hadoop 2.6.0 集群
我主要是做数据抽取和文本分析的工作,最近因为要支持 Hive 数据的抽取,所以准备搭建一个 Hadoop + Hive 的集群平台,原来准备直接用 CDH 的,但是由于公司网络或者其它原因,我试了几遍都没有成功。索性还是单独来搭建和手动配置,我记得以前这么做其实是很简单的。
我这里最终搭建用的包是 CDH 5.10.0 的包 hadoop-2.6.0-cdh5.10.0.tar.gz,我看了 CDH 5.x 的版本的 Hadoop 都是 2.6.0 的版本,原来觉得很奇怪,后来在加入其它组件的时候才发现,Hadoop 2.x 的话目前来说,是兼容性最好的,很多组件的默认测试的环境都是 Hadoop 2.6.0,所以如果你要搭建 Hadoop 2.x 的集群,最好就选用这个版本。
然后 CDH 的 Hadoop 包和 apache 的原生包搭建、配置和使用其实是一样的,没有多少区别,最大的不同就是 CDH 的包之间兼容性好,比如你如果要搭建原生的 Hadoop + Hive 平台,就算你选择的版本的 CDH 一样的,搭建的过程中你也需要适配各种 jar 包的兼容性,而 CDH 做的工作就是把这些兼容性适配好了,做到了开箱即用。这两种环境我都搭建和使用过,所以比较有体会,
CDH 的 Hadoop 包下载地址:hadoop-2.6.0-cdh5.10.0.tar.gz,其他组件比如 Hive 什么的,可以在 http://archive.cloudera.com/cdh5/cdh/5/ 目录下搜索到 tar.gz 的压缩包。
apache Hadoop 包下载地址 hadoop-2.6.0.tar.gz。
环境
hd-node1 为 NameNode 主节点。
192.190.20.13 hd-node1
192.190.20.14 hd-node2
192.190.20.15 hd-node3
我搭建的不是生产环境,为了快速方便,没有新建用户,全部在 root 用户下操作。
准备好三台 CentOS 7 虚拟机,全部安装配置好 JDK,我选用了 JDK 1.8.0_112 的版本。
[root@hd-node1 ~]# java -version
java version "1.8.0_112"
Java(TM) SE Runtime Environment (build 1.8.0_112-b15)
Java HotSpot(TM) 64-Bit Server VM (build 25.112-b15, mixed mode)
[root@hd-node1 ~]#
需要注意的是,不管用哪种方式搭建 Hadoop 集群,在安装准备虚拟机的时候最好不要使用最小模式或者服务器模式,先安装桌面环境,然后切换到服务器模式。这样的话,省去了系统依赖的排查和安装的时间,因为 Hadoop 一整套东西依赖的系统包还是蛮多的。
网络配置
装好虚拟机后,设置虚拟机为静态 IP,并修改一下虚拟机的主机名和 IP 地址,还需要增加 IP 与主机映射,每个节点都需要对应配置。
修改主机名
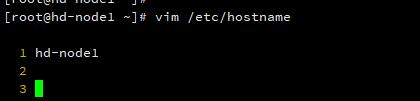
分别修改各个节点的虚拟机主机名为 hd-node1、hd-node2、hd-node3。
# vim /etc/hostname
hd-node1
设置静态 IP
集群的 IP 地址肯定不能使用 DHCP 自动获取 IP,需要修改 IP 地址并设置为静态。
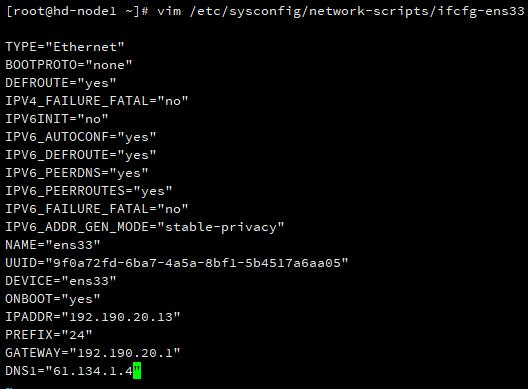
vim /etc/sysconfig/network-scripts/ifcfg-ens33
现在虚拟机 CentOS 的网卡名称一般都是 ifcfg-ens** 的样子,不是 eth。
主要的几个配置项:
BOOTPROTO="static" # 设置为静态IP
ONBOOT=yes # 启动系统的时候打开网卡
IPADDR="192.190.20.13" # 设置IP
NETMASK="255.255.255.0" # 设置子网掩码
GATEWAY="192.190.20.1" # 设置网关
DNS1="61.134.1.4" # 设置 DNS
DNS2="8.8.8.8"
然后重启网络服务,查看配置生效。
systemctl restart network
配置 IP 与主机映射
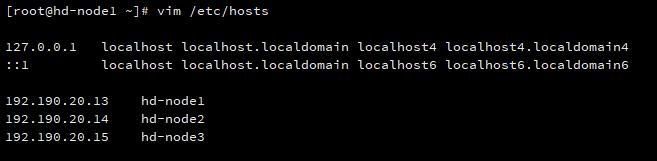
# vim /etc/hosts
192.190.20.13 hd-node1
192.190.20.14 hd-node2
192.190.20.15 hd-node3
ssh 免密登录
在每台虚拟机的根目录 root 下,创建 ssh 公钥:
ssh-keygen –t rsa
连续回车,默认生成路径为当前用户的 home 目录,提示输入密码的时候不要输入,一直默认、回车,系统自动生成图形公钥。
在主节点 hd-node1 中,进入 /root/.ssh 目录,并将公钥写到 authorized_keys 文件中。
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
然后其它节点 hd-node2 和 hd-node3 分别进入 .ssh 目录,把 id_rsa.pub 拷贝到 hd-node1 中,注意重命名以区分。
# hd-node2 上
scp /root/.ssh/id_rsa.pub hd-node1:/root/.ssh/id_rsa.pub.node2
# hd-node3 上
scp /root/.ssh/id_rsa.pub hd-node1:/root/.ssh/id_rsa.pub.node3
拷贝过来后,再在 hd-node1 上面把其它节点的公钥写入到我们刚刚写进去的 authorized_keys 文件中。
# hd-node1 上
cat id_rsa.pub.node2 >> authorized_keys
cat id_rsa.pub.node3 >> authorized_keys
我们查看一下 authorized_keys 文件,包含了三台虚拟机的公钥文件。

更改 authorized_keys 文件属性,使之不能被修改:
chmod 600 authorized_keys
在主节点 hd-node1 的 .ssh 目录下,将生成的 authorized_keys 复制到各个从节点:
scp /root/.ssh/authorized_keys hd-node2:/root/.ssh/
scp /root/.ssh/authorized_keys hd-node3:/root/.ssh/
然后在每台主机上,使用 ssh 对方主机名 验证是否互相免密码登录(包括自己也验证一下),如果不需要密码,则设置成功。
ssh hd-node1
ssh hd-node2
ssh hd-node3
注意登录成功后,注意
logout退出对方登录,以免误操作。
如果不成功,则要修改 ssh 配置。
# vim /etc/ssh/ssh_config
RSAAuthentication yes
PubkeyAuthentication yes
StrictModes no
如果你生成密钥文件不是在默认的用户目录下的 .ssh 目录,则需要修改 AuthorizedKeysFile 项。
修改好后重启 ssh 服务。
systemctl restart sshd
Hadoop 2.6.0 的解压安装与配置
我是从 cloudera 官网下载 hadoop-2.6.0-cdh5.10.0.tar.gz 版本的压缩包。
在 主节点 hd-node1 中,解压 Hadoop 压缩包到 /opt/ 中:
tar -zxvf hadoop-2.6.0-cdh5.10.0.tar.gz -C /opt
创建缓存数据存储目录
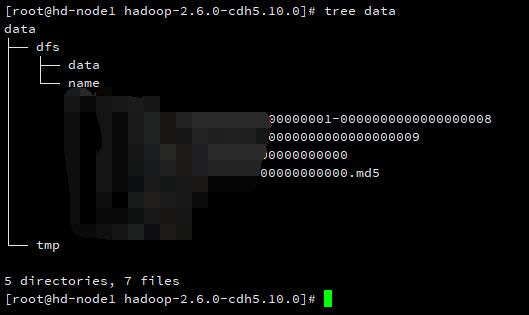
在 Hadoop 目录下创建 data 目录。
cd /opt/hadoop-2.6.0-cdh5.10.0/
mkdir data
cd data
mrdir tmp
mkdir dfs
cd dfs
mkdir data
mkdir name
进入到 Hadoop 的配置目录:
cd /opt/hadoop-2.6.0-cdh5.10.0/etc/hadoop
现在修改配置文件。
core-site.xml
vim core-site.xml
修改配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.0-cdh5.10.0/data/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hd-node1:8020</value>
</property>
</configuration>
hdfs-site.xml
vim hdfs-site.xml
配置 HDFS 相关信息:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hd-node1:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.6.0-cdh5.10.0/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.6.0-cdh5.10.0/data/dfs/data</value>
</property>
</configuration>
mapred-site.xml
vim mapred-site.xml
配置 Mapreduce 与 YARN。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
vim yarn-site.xml
配置 YARN。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hd-node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
hadoop-env.sh
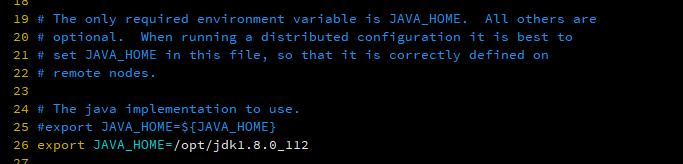
找到 #export JAVA_HOME=${JAVA_HOME} 修改 Java home 目录。
分发
在主节点上配置好后,将 Hadoop 复制到各个节点对应位置上。
scp -ra /opt/hadoop-2.6.0-cdh5.10.0 hd-node1:/opt/
scp -ra /opt/hadoop-2.6.0-cdh5.10.0 hd-node2:/opt/
Hadoop 环境变量配置
在 /etc/profile 中配置 Hadoop 环境变量,可以方便的使用 hdfs 等命令。

启动
进入主节点 hd-node1 的 hadoop 的目录下。
格式化 NameNode
第一次启动,先格式化 NameNode,相当于格式化逻辑磁盘。
./bin/hdfs namenode -format
启动集群
按顺序,先启动 DFS,然后启动 YARN。
./sbin/start-dfs.sh
./sbin/start-yarn.sh
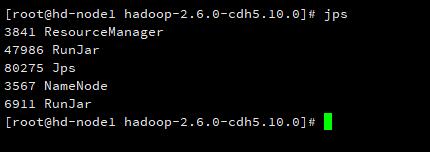
然后在主节点 hd-node1 输入 jps 可以查看到 NameNode、Jps 和 ResourceManager 进程。
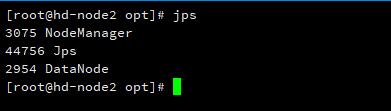
在从节点 hd-node2 输入 jps 可以查看到 Jps、NodeManager 和 DataNode 进程。
尝试使用一下 HDFS。
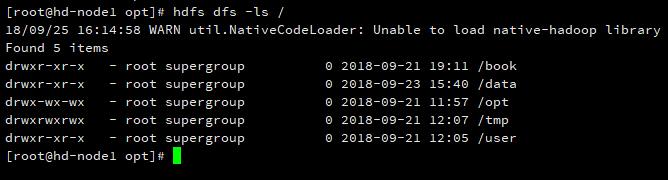
OK,没问题。到目前为止,集群就正式搭建好了。
关闭集群
按照启动的顺序倒过来关闭服务,先关闭 YARN,在关闭 DFS。
./sbin/stop-dfs.sh
./sbin/stop-yarn.sh