ElasticSearch 6.0.0 安装配置
一、 先决条件
安装好 JDK1.8u152;
从官网下载好 elasticsearch 二进制的 tarball,解压后放置在合适的安装位置,绿色无安装,例如 /opt/es/ 目录下;
安装 nodejs 环境,可以参考本站写的简单安装文档,如果不使用 elasticsearch-head,可以跳过;
注: $ES_HOME 代表 es 的安装位置。
二、 单实例安装运行
单实例非常简单,运行:$ES_HOME/bin/elasticsearch 命令。
处于安全方面的考虑,ElasticSearch 不再允许使用 root 账户启动,请使用普通账户启动它。
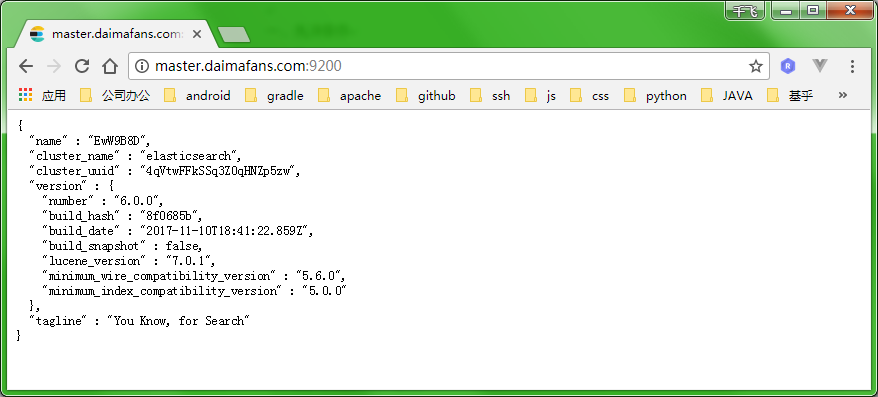
等待服务初始化并完成启动后,可以查看到 es 默认监听的 9200 端口。
使用 curl 或者浏览器检查服务启动状态:
三、 安装启动常见错误及解决
1. 不允许 root 启动
报错详情:
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
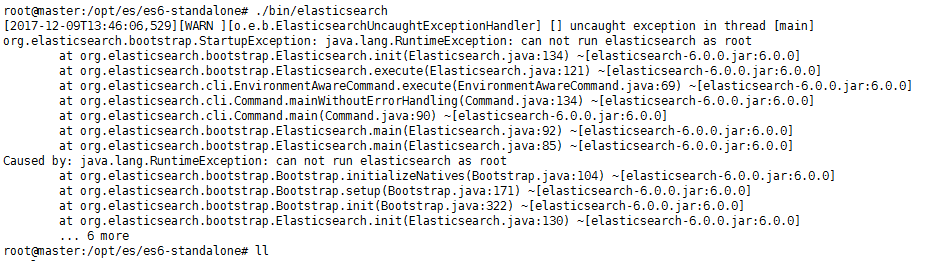
这个其实很简单,而且在最新版本中似乎只能这么做了,那就是使用非 root 用户启动 elasticsearch,可以使用现有的非 root 用户启动,也可以单独为 elasticsearch 添加一个组和用户。前者测试方便,后者比较规范一点。
只需要使用 groupadd 添加一个组,用 useradd 添加一个用户,然后将 $ES_HOME 目录的组和所属权限赋予就行了。
2. 外部主机访问
默认情况下,ES 9200 端口不能被外部主机访问,需要修改 $ES_HOME/config/elasticsearch.yml 配置文件,修改网络绑定端口。
找到 network.host 并修改:

如果有需要,也可进行其他项配置。
配置文件中罗列了部分常用的配置项,如果需要完整了解,请参阅官方包中文档。
3. 系统配置限制检查
如上一节修改绑定端口后启动,会出现下面的错误:
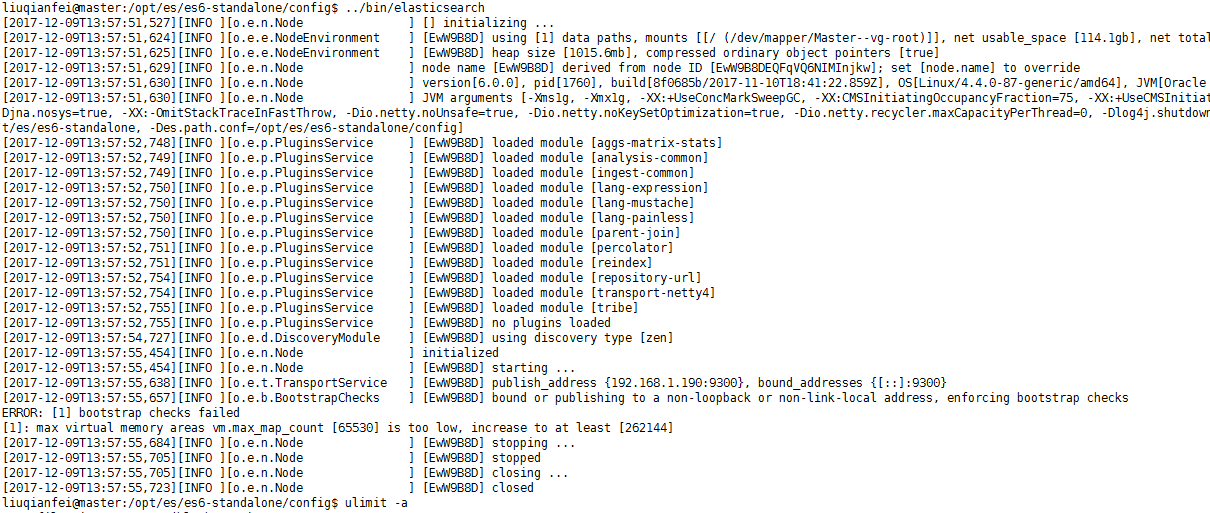
进程最大打开文件数限制
报错详情:
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
这个是 linux 下常见的错误,主要是因为 linux 会限制进程的最大打开文件数,只需要简单配置一下即可解决,在 ES 的官方文档中提供了两种解决方案。
这里我们只看系统基本的配置这种方式。
打开 /etc/security/limits.conf,添加如下配置:
#* soft core 0
#* hard rss 10000
#@student hard nproc 20
#@faculty soft nproc 20
#@faculty hard nproc 50
#ftp hard nproc 0
#@student - maxlogins 4
elasticsearch - nofile 65536 # 添加这一行
# End of file
保存即可,无需重启。
这里的 elasticsearch 是用户名,表明这个配置只对 elasticsearch 用户生效,如果你用来启动 elasticsearch 的用户名不是这个,那么你需要按你实际的用户名修改。
使用的虚拟内存限制
报错详情:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
这个是 ES 使用的虚拟内存,官方文档 给出了解决方案:
elasticsearch@master:/opt/es/es6-standalone$ sudo sysctl -w vm.max_map_count=262144
调大虚拟内存即可。

重新启动,就可以正常访问了,现在我们可以在任何机器上访问 ES 了。
不过上面的命令只生效一次,如果想要持久化永久生效,则请在 /etc/sysctl.conf 文件中加入以上配置: vm.max_map_count=262144,使用 sysctl -p 使之立即生效。
四、 安装 head 插件
插件地址:https://github.com/mobz/elasticsearch-head
直接下载 ZIP 包或者 git clone 下来。
因为 es 和 es-head 服务属于两个独立进程,还需要一些相关配置,才能使用 es-head 来管理 es 实例。
首先,修改 $ES_HOME/config/elasticsearch.yml:
http.cors.enabled: true
http.cors.allow-origin: "*"
$ bin/elaticsearch –d 使 es 在后台运行,请再次检查确认服务是否正常启动,如果异常,可以查看 $ES_HOME/logs/elasticsearch.log 查看详细日志。
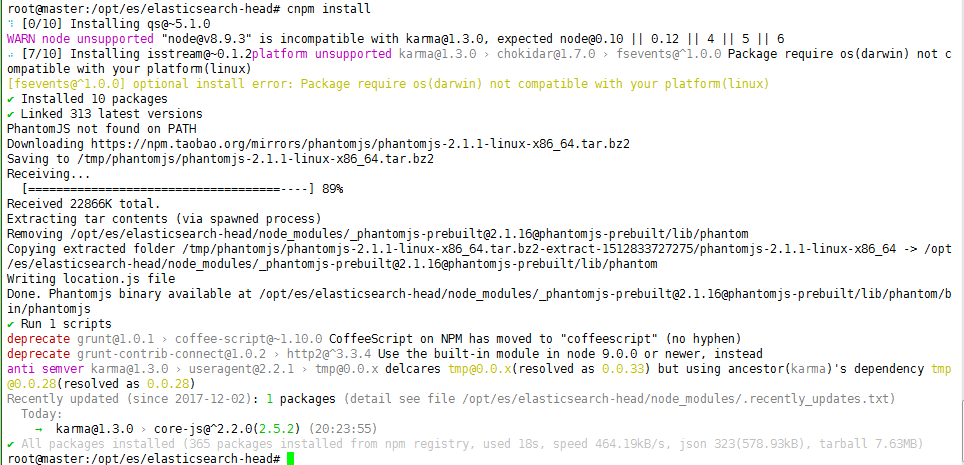
现在,使用 npm 或 cnpm 下载 elasticsearch-head 依赖,请 cd 到 elasticsearch-head 目录,执行:
# cnpm install // 或者 npm install,不再赘述
参考 git 上的安装运行文档,要启动运行head插件,请在目录下执行:
# cnpm run start
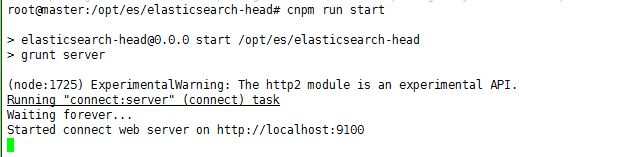
可以看到 elasticsearch-head 绑定 9100 端口,使用浏览器访问,输入服务地址,查询 es 健康状态:
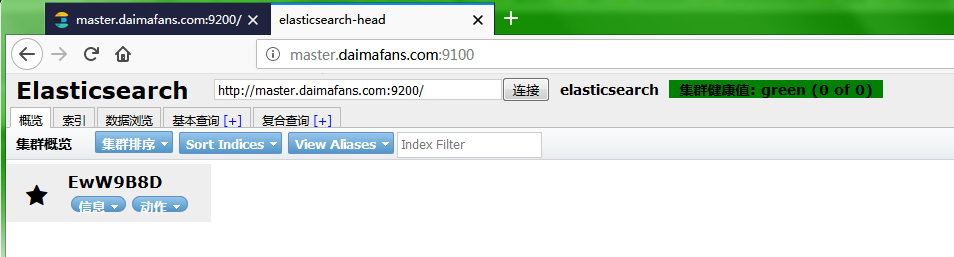
至此,elasticsearch-head 插件安装完成。
五、 集群配置
如果前面单机的测试环境搭建没有问题,集群就非常简单了。
我们这里做一个3台机子的主从配置。
主节点
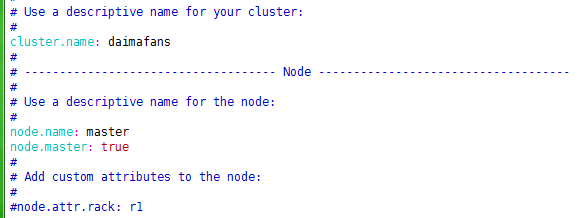
在上面单机配置的基础上,首先修改master节点的$ES_HOME/config/elasticsearch.yml文件,修改配置项:
cluster.name,集群名称,这个所有主从节点都要一致;
node.name: master,节点名称,以与集群中其他节点区分开;
node.master: true,主节点专用,标识此节点为master。
从节点1
从节点首先配置 cluster.name,保持和主节点一致,然后配置 node.name: slave1。
从节点还需要配置一个 discovery.zen.ping.unicast.hosts 项:

["master.daimafans.com"] 列表中为在本节点上可以 ping 通的主机地址。
然后启动本节点。
从节点2
配置和上面基本相同。不同点: cluster.name: slave2。
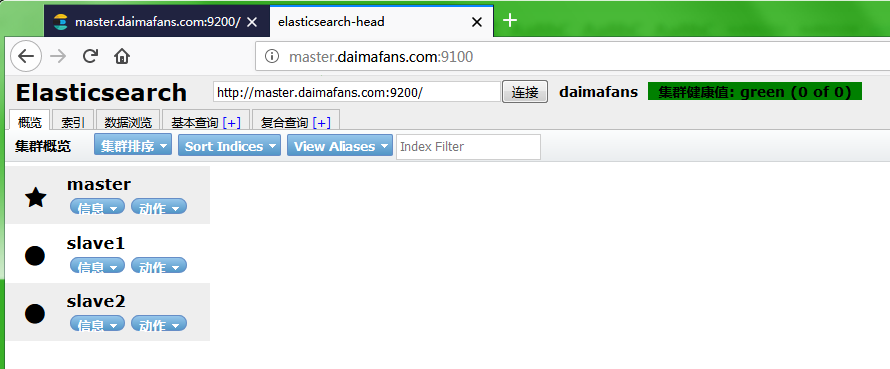
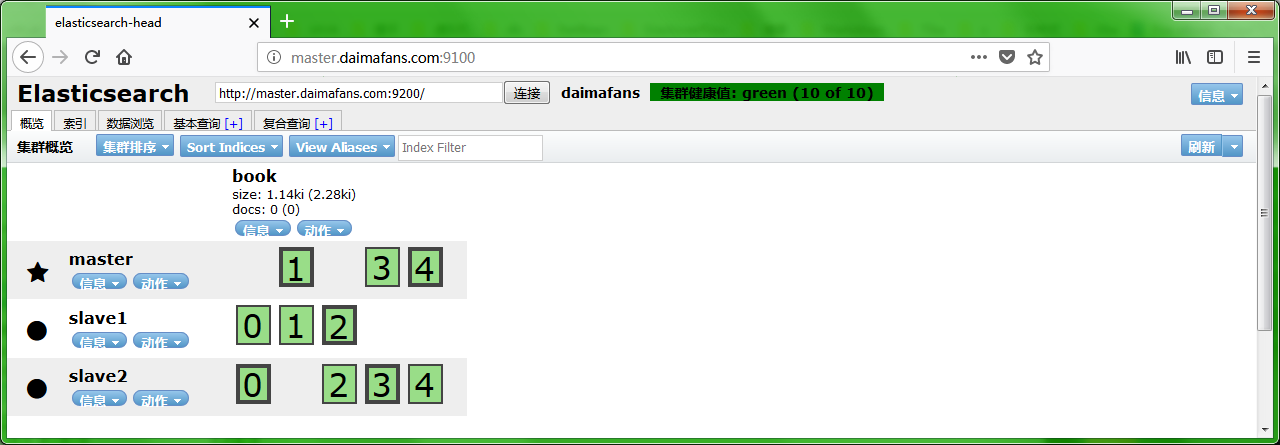
查看集群状态
使用 elasticsearch-head 查看集群状态:
六、 基本概念和使用示例
- 索引:含有相同属性的文档集合
- 类型:索引可以定义一个或多个类型,文档必须属于一个类型
- 文档:文档是可以被索引的基本数据单位
- 分片:每个索引都有多个分片,每个分片是一个 Lucene 索引
- 备份:拷贝一份分片就完成了分片的备份
API基本格式: http://ip:port/index/type/documentId
常用 HTTP 动词: GET/PUT/POST/DELETE
索引创建
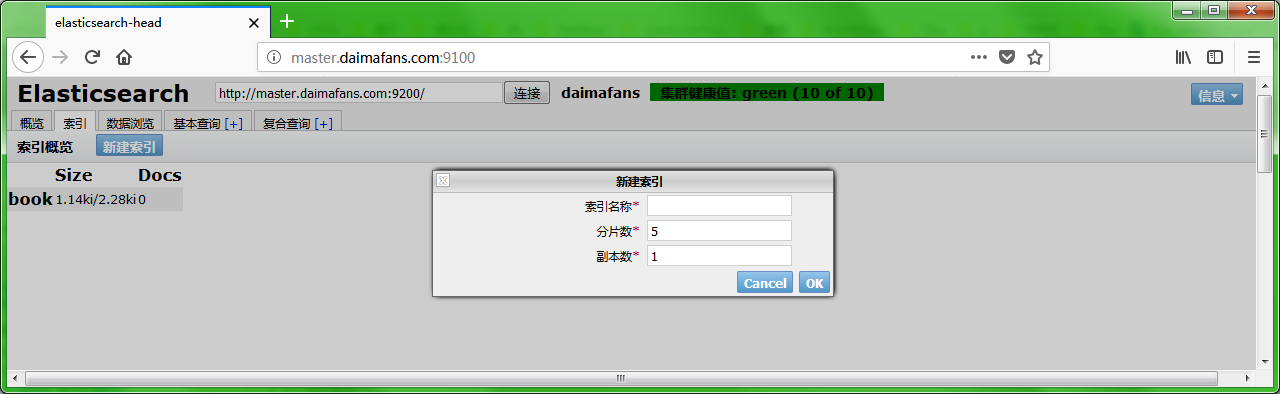
ES 服务启动为后台进程,可以使用:
停止服务使用
ps和kill管理。