Tesseract OCR 使用完全指南教程
前言
前段时间工作中发现如果能够将一些相同标准的图片中文字识别出来,能提升不少我们的用户体验。于是就看了一下图片文字识别相关的功能。
首先就是了解了一下各大厂的 api,那识别率自然是很高,效果非常的不错,但问题就是,限制调用次数并且模型不受自己的控制,或者就需要充钱使你变强。 (这里贴一个别人的分享吧:Java-基于百度API的图片文字识别(支持中文,英文和中英文混合) - TheLoveFromWSK - CSDN博客)
然后就自己了解了下 ocr 和 tesseract。本文主要是一个 helloworld 版本的 tesseract 入门使用教程...所以还请大佬轻拍
介绍
OCR:光学字符识别(英语:Optical Character Recognition,OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
本文主要讲的是 Tesseract-OCR:Tesseract 是 Ray Smith 于 1985 到 1995 年间在惠普布里斯托实验室开发的一个 OCR 引擎,曾经在 1995 UNLV 精确度测试中名列前茅。但 1996 年后基本停止了开发。2006 年,Google 邀请 Smith 加盟,重启该项目。目前项目的许可证是 Apache 2.0。该项目目前支持 Windows、Linux 和 Mac OS 等主流平台。但作为一个引擎,它只提供命令行工具。
Tesseract 安装
有兴趣研究源码的同学可以看下GitHub地址:GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository) 下载链接,mac、windows、linux 都有,可取所需:Downloads · tesseract-ocr/tesseract Wiki · GitHub
windows
-
下载完成后直接执行exe文件,安装到对应的文件夹即可。
-
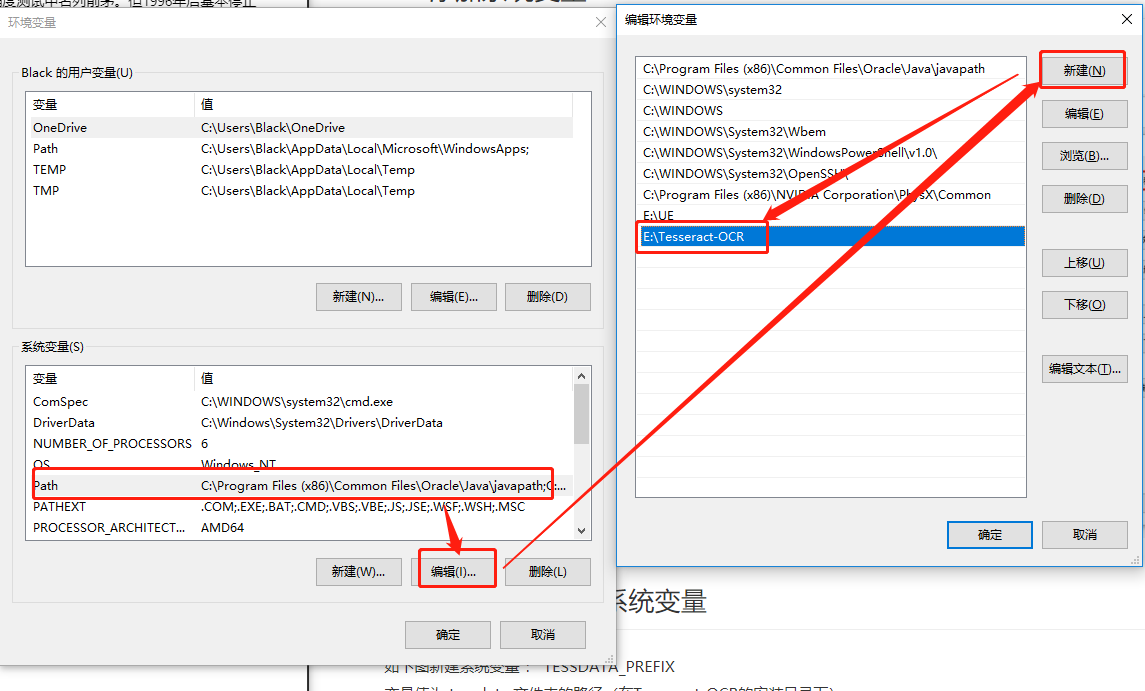
配置环境变量:
在 Path 中新增环境变量,地址是 Tesseract-ocr 的安装目录
-
添加 tessdata 系统变量
在系统变量中添加
TESSDATA_PREFIX,变量值为 Tesseract-ocr 目录中的tessdata文件夹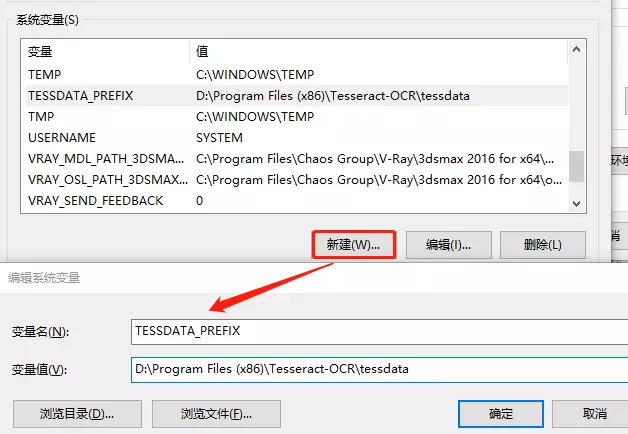
-
进入 cmd 检查是否安装完成
tesseract -v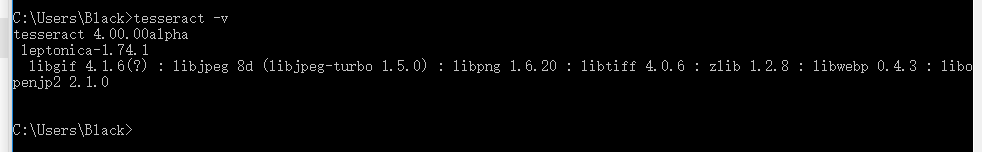
出现如上图一样的东西那就是安装 ok 啦,第一步也就搞完了
使用 Tesseract
安装成功之后呢,自然是要 try 一下的
-
准备个图片 PNG,JPG 都是可以的(具体支持哪些格式就不一一列举了,这里我就用 png 了)

-
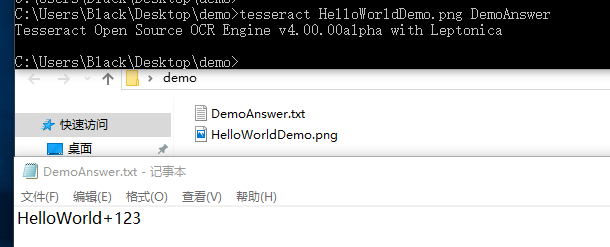
然后敲命令
tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...]这里解释一下,就是 tesseract [图片的地址+名字+后缀] [输出的地址+名字] 例如:

-
这样就会在目录下申城一个 DemoAnswer.txt 的文件
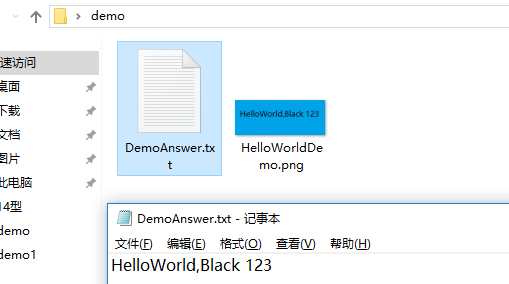
ok,结果正确
但是这里如果是中文呢?重复上面的操作试下
-
中文识别
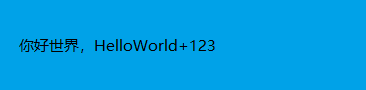
这里会发现重复上面的操作,中文丢失了
tesseract imagename outputbase [-l lang]这句命令中的
[-l lang]是设置识别语言的,默认是英语,所以如果需要识别中文还需要去下载中文的字库 (其实细心的同学可能在安装的时候有注意到,就已经自动安装了字库) 去到 tesseract-ocr 的安装目录中的 tessdata 目录下查看***.traineddata就是字库。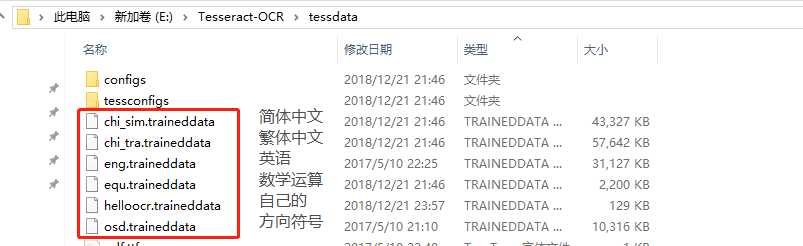
4.1 下载中文字库
如果安装的时候没有下载的话,可以来这里找自己需要的字库下载 Data Files · tesseract-ocr/tesseract Wiki · GitHub
将下载的字库放到 tessdata 目录中即可
4.2 敲命令
tesseract HelloWorldDemo.png DemoAnswer -l chi_sim
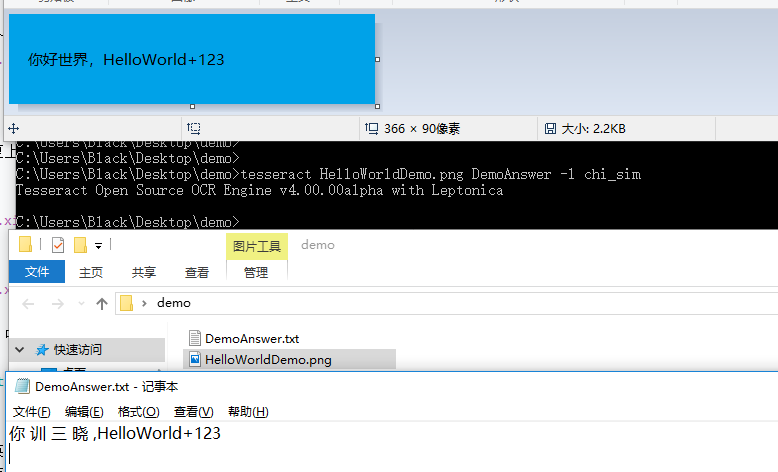
这里就出现了一点点的瑕疵,中文识别的有问题
这是因为使用的字库跟我们的字体是有差异的,所以如果需要能识别我们图片中的字体,需要去训练我们自己的字库
训练模型
步骤:(转自tesseract的github)
Prepare training text.
准备你的训练文本
Render text to image + box file. (Or create hand-made box files for existing image data.)
将文本转为 image+box 文件.(如果你已经有 image 文件的话,只需要手动生成 box 文件)
Make unicharset file.
生成 unicharset 文件
Optionally make dictionary data.
有选择性的生成字典数据
Run tesseract to process image + box file to make training data set.
运行 tesseract 来处理之前的 image+box 文件生成一个训练数据集合
Run training on training data set.
在训练数据集合的基础上进行训练
Combine data files.
合并数据文件
-
将图片的命名改为
[lang].[fontname].exp[num].tif(改后缀建议通过另存为的方法来选择 tif)例如:BlackLang.HelloWorldDemo.exp0.tif
-
生成 box 文件
提一张官网的图

输入路径和输出路径文件名为了方便我这里就保持一直了 因为我们训练的是中文,所以加上
-l chi_sim,这样减少我们在调整的时候的差异。实际的命令:tesseract BlackLang.HelloWorldDemo.exp0.tif BlackLang.HelloWorldDemo.exp0 -l chi_sim batch.nochop makebox这样就会在目标目录中生成一个
.box的文件,如下图
好奇的同学可以点开
.box的文件看下,其实里面就是每个字的坐标之类的东西
-
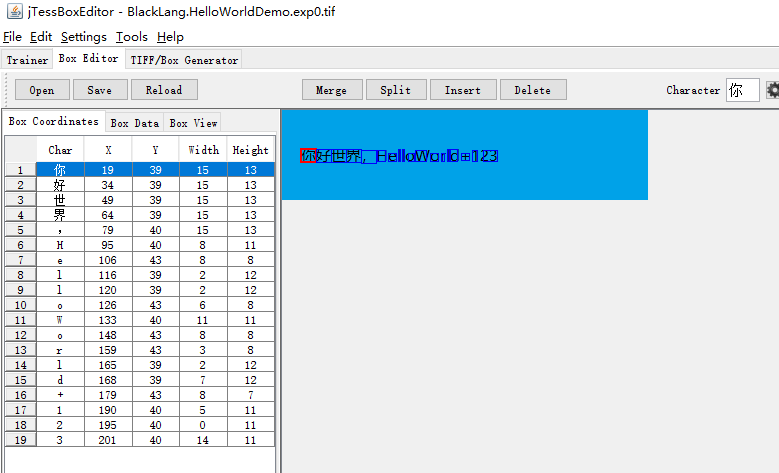
使用 jTessBoxEditor
这里为了方便我们矫正 box 文件,这里使用一个工具 jTessBoxEditor: VietOCR - Browse /jTessBoxEditor at SourceForge.net
安装好了之后,打开 jTessBoxEditor,点击 open,选择对应的 tif(如果这里 tif 和 box 不在一个目录中会有问题哦)
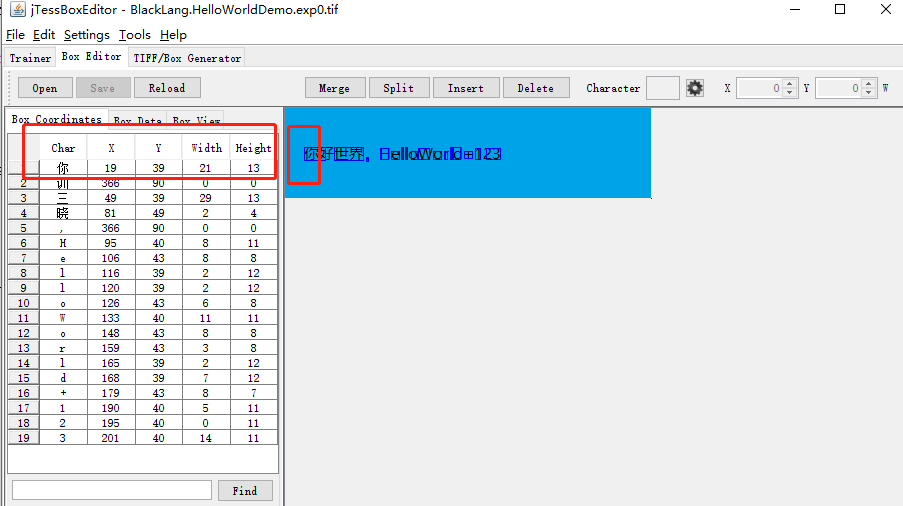
3.1 在 Box Coordinates 中通过调整 x、y、w、h 来框住对应的字,然后再 char 中输入正确的字
3.2 在 Box View 中可以看到每个字的放大图,来确认是否完全选中
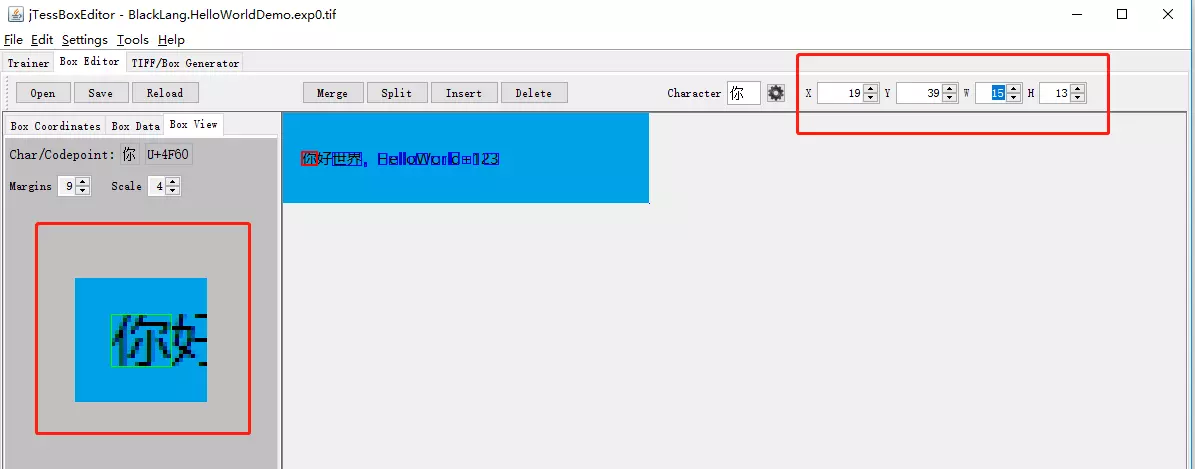
这样将每个字都校验一遍后,点击 save 即可:
- 训练
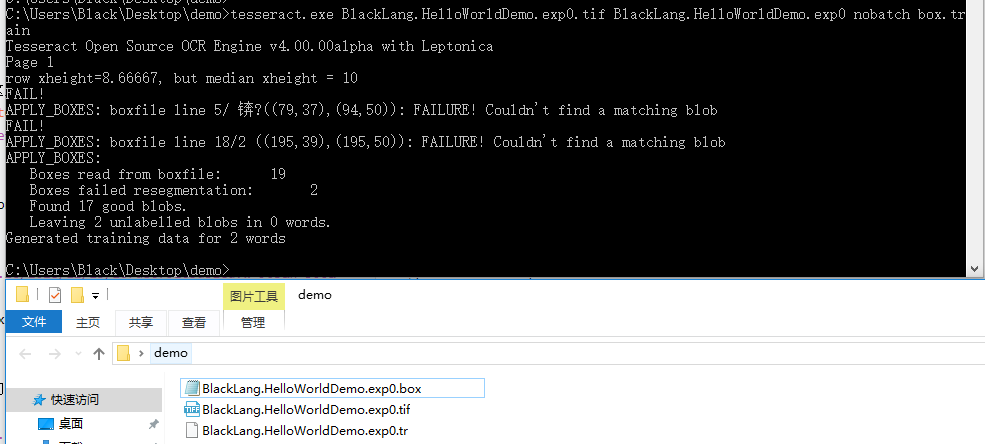
4.1 生成 tr 文件
输入命令:tesseract.exe [tif图片文件名] [生成的tr文件名] nobatch box.train
tesseract.exe BlackLang.HelloWorldDemo.exp0.tif BlackLang.HelloWorldDemo.exp0 nobatch box.train
4.2 生成 unicharset 文件
输入命令:unicharset_extractor.exe [box文件名]
unicharset_extractor.exe BlackLang.HelloWorldDemo.exp0.box
这里如果你有多个图片需要去生成字库的话,就需要合并成一个 char 集合
输入命令:unicharset_extractor.exe [第一个box文件名] [第二个box文件名] ··· 这里演示 demo 就只用一个 box
4.3 定义字体特征文件 font_properties
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
这里的 tontname 必须要和 [lang].[fontname].exp[num].box 保持一致; <italic> 、<bold> 、<fixed> 、<serif>、<fraktur> 的取值为 1 或 0,表示字体是否具有这些属性。
这里我们在目录中创建一个名字为 font_properties 的文件,内容如下:
HelloWorldDemo 0 0 0 0 0
这是我们的目录中的文件如下: 一个目标图片 .tif,一个分析 .box,一个训练结果.tr,一个字符集 unicharset,一个特征文件 font_properties
4.4 生成字典 输入命令:
mftraining.exe -F font_properties -U unicharset -O BlackLang.unicharset BlackLang.HelloWorldDemo.exp0.tr
#这里如果有多个tr就连在后面写多个tr即可
cntraining.exe BlackLang.HelloWorldDemo.exp0.tr
#这里如果有多个tr就连在后面写多个tr即可
如图:
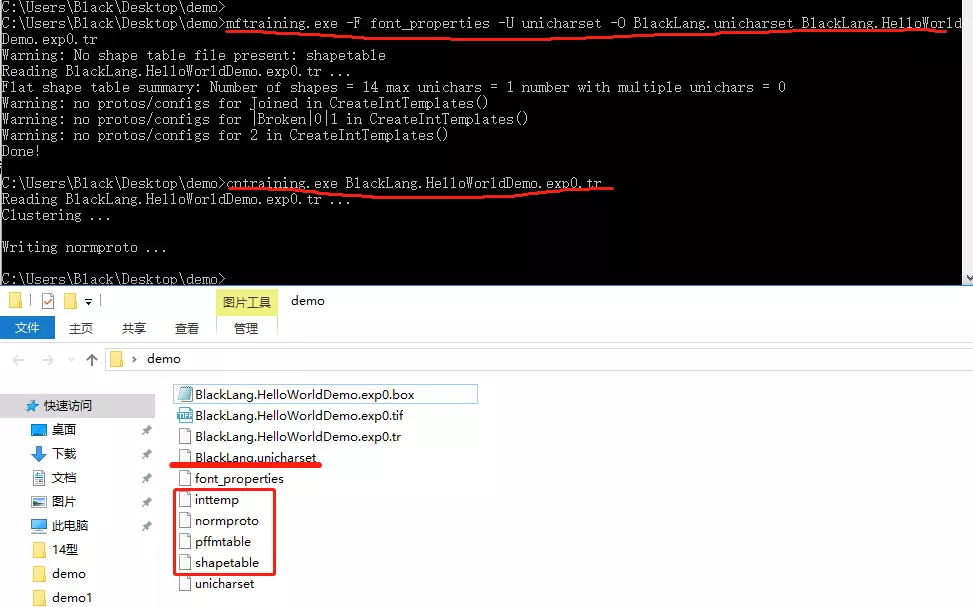
执行完成之后,发现多了 5 个文件。然后讲这 5 个文件都改成 lang 开头,即 [lang].XXX (inttemp、pffmtable、normproto、shapetable;BlackLang.unicharset 已经是了就不用改了)
有兴趣的同学可以通过编辑器打开看看里面都是啥,会发现里面都是一些蛮有意思的乱码哈哈哈
4.5 合并文件 输入命令:
combine_tessdata BlackLang.
#combine_tessdata [lang].
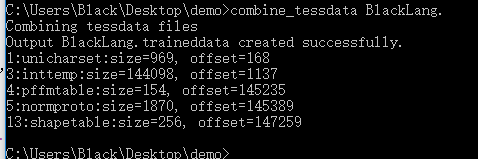
这里需要注意的是 [lang] 后面还有个点,很关键 然后是执行的结果中,1、3、4、5、13 这些都不是 -1,这样一个新的语言文件就生成了,或者说是一个新的字体文件--- [lang].traineddata
然后将刚刚生成的 [lang].traineddata 复制到 tesseract-ocr 的 tessdata 中 再来执行命令:
tesseract HelloWorldDemo.png answer -l BlackLang
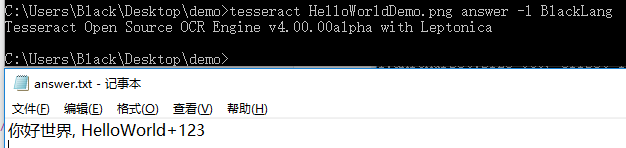
这样原本的图片就能解析成功了
结束
这只是一个非常 demo 的训练,正常现在生产中使用这个还是万万不够的,需要对某个字体的全部的汉子进行大量的训练才行 总的来说,tesseract 对中文的识别能力还是很差的,更别说是手写的中文了,那识别率基本是没有。但是对英文还有数字的识别率还是很可观的。 这里也只是一个简单的对于 tesseract 分享记录而已~
现在已经有很多被封装后的 ocr 例如 pyocr 啊,tess4J 啊之类的,或者各大厂提供的 api 这些的识别率就很高了毕竟模型已经训练的很好了,这些就下次再说吧