Hadoop 生产环境规格的配置
节点规划
| hd-node1/192.190.20.13 | hd-node2/192.190.20.14 | hd-node3/192.190.20.15 | hd-node4/192.190.20.16 | hd-node5/192.190.20.17 | |
|---|---|---|---|---|---|
| namenode | 是 | 是 | 否 | 否 | 否 |
| datanode | 否 | 否 | 是 | 是 | 是 |
| resourcemanager | 是 | 是 | 否 | 否 | 否 |
| journalnode | 是 | 是 | 是 | 是 | 是 |
| zookeeper | 是 | 是 | 是 | 是 | 是 |
Journalnode 和 ZooKeeper 保持奇数个,这点大家要有个概念,最少不少于 3 个节点。
软件规划
| 软件 | 版本 | 位数 | 说明 |
|---|---|---|---|
| jdk | 1.8 | 64位 | 最新稳定版 |
| centos | centos7(1611) | 64位 | |
| zookeeper | Apache zookeeper3.4.10 | 稳定版本 | |
| hadoop | hadoop-2.6.0-cdh5.10.0 | 稳定版本 |
用户规划
| 节点名称 | 用户组 | 用户 |
|---|---|---|
| hd-node1 | hadoop | hadoop |
| hd-node2 | hadoop | hadoop |
| hd-node3 | hadoop | hadoop |
| hd-node4 | hadoop | hadoop |
| hd-node5 | hadoop | hadoop |
目录规划
| 用途 | 路径 |
|---|---|
| 所有软件目录 | /home/hadoop/app/ |
| 所有数据和日志目录 | /home/hadoop/data/ |
时钟同步
所有节点的系统时间要与当前时间保持一致。查看当前系统时间:
[root@hd-node1 ~]# date
Tue Dec 11 00:52:35 CST 2018
[root@hd-node1 ~]#
如果系统时间与当前时间不一致,进行以下操作,将所有主机的时区调整一致。
[root@hd-node1 ~]# cd /usr/share/zoneinfo/
[root@hd-node1 zoneinfo]# ls // 找到 Asia
[root@hd-node1 zoneinfo]# cd Asia/
[root@hd-node1 Asia]# ls // 找到 Shanghai
[root@hd-node1 Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime // 当前时区替换为上海
我们可以同步当前系统时间和日期与 NTP(网络时间协议)一致。
[root@hd-node1 Asia]# yum install ntp // 如果ntp命令不存在,在线安装ntp
[root@hd-node1 Asia]# ntpdate pool.ntp.org // 执行此命令同步日期时间
[root@hd-node1 Asia]# date // 查看当前系统时间
其它细节可以参考 《CentOS NTP 时间同步服务安装和局域网同步》
hosts 文件检查
所有节点的 hosts 文件都要配置静态 ip 与 hostname 之间的对应关系。
[root@hd-node1 ~]# vim /etc/hosts
192.190.20.13 hd-node1
192.190.20.14 hd-node2
192.190.20.15 hd-node3
192.190.20.16 hd-node4
192.190.20.17 hd-node5
禁用防火墙
所有节点的防火墙都要关闭,查看防火墙状态:
[root@hd-node1 ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
[root@hd-node1 ~]#
如果不是上面的关闭状态,则需要关闭防火墙。
[root@hd-node1 ~]# systemctl disable firewalld // 永久关闭fanghuoq
[root@hd-node1 ~]# systemctl stop firewalld // 关闭,停止防火墙运行
创建 hadoop 用户
为所有主机创建 hadoop 普通用户。
[root@hd-node1 ~]# groupadd hadoop // 创建用户组
[root@hd-node1 ~]# useradd -g hadoop hadoop // 新建 hadoop 用户并增加到 hadoop 工作组
[root@hd-node1 ~]# passwd hadoop // 设置密码
配置 SSH 免密码通信
这里简单说一下,不清楚的可以参考前面的 《CentOS7 搭建 Hadoop 2.6.0 集群》,本章的安装包也可以在里面找到。
[root@hd-node1 ~]# su hadoop // 切换到 hadoop 用户下
[hadoop@hd-node1 root]$ cd // 切换到 hadoop 用户目录
[hadoop@hd-node1 ~]$ ssh-keygen -t rsa // 执行命令,一路回车,不要输入密码,生成秘钥
[hadoop@hd-node1 ~]$ cd .ssh
[hadoop@hd-node1 .ssh]$ ls
id_rsa id_rsa.pub
[hadoop@hd-node1 .ssh]$ cat id_rsa.pub >> authorized_keys // 将公钥保存到 authorized_keys 认证文件中
[hadoop@hd-node1 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub
[hadoop@hd-node1 .ssh]$ cd ..
[hadoop@hd-node1 ~]$ chmod 700 .ssh // 给目录和文件赋权限,否则有些时候免密不生效
[hadoop@hd-node1 ~]$ chmod 600 .ssh/*
[hadoop@hd-node1 ~]$ ssh hd-node1 // 第一次执行需要输入 yes
[hadoop@hd-node1 ~]$ ssh hd-node1
每个节点都执行上面同样的操作,然后将所有节点中的公钥 id_rsa.pub 拷贝到 hd-node1 节点中的 authorized_keys 文件中,分别在 hd-node 2-5 上执行:
[hadoop@hd-node1 .ssh]$ cat ~/.ssh/id_rsa.pub | ssh hadoop@hd-node1 'cat - >> ~/.ssh/authorized_keys'
然后在 hd-node1 上查看 authorized_keys 文件:
[hadoop@hd-node1 ~]$ cat ~/.ssh/authorized_keys
ssh-rsa ...... hadoop@hd-node1
ssh-rsa ...... hadoop@hd-node2
ssh-rsa ...... hadoop@hd-node3
ssh-rsa ...... hadoop@hd-node4
ssh-rsa ...... hadoop@hd-node5
免密认证文件做好了,然后将 hd-node1 中的 authorized_keys 文件分发到所有节点上面。
[hadoop@hd-node1 .ssh]$ scp -r authorized_keys hadoop@hd-node2:~/.ssh/
[hadoop@hd-node1 .ssh]$ scp -r authorized_keys hadoop@hd-node3:~/.ssh/
[hadoop@hd-node1 .ssh]$ scp -r authorized_keys hadoop@hd-node4:~/.ssh/
[hadoop@hd-node1 .ssh]$ scp -r authorized_keys hadoop@hd-node5:~/.ssh/
在主机间通过 ssh 相互访问,如果都能无密码访问,代表 ssh 配置成功。(记得登录上对方主机后使用 logout 退出登录,防止操作混乱)
脚本工具
在 hd-node1 节点上创建 /home/hadoop/tools 目录。
[hadoop@hd-node1 ~]$ mkdir /home/hadoop/tools
[hadoop@hd-node1 ~]$ cd /home/hadoop/tools
将本地脚本文件上传至 /home/hadoop/tools 目录下。这些脚本大家如果能看懂也可以自己写,如果看不懂直接使用就可以。其中 deploy.sh 脚本可以将主节点配置好的安装包分发到其它主机,runRemoteCmd.sh 脚本可以在其它主机上执行命令。deploy.conf 配置文件中把集群的节点按第一节 “节点规划” 中进程分了几个类别,因为有些命令并不是要在所有主机上执行的。
[hadoop@hd-node1 tools]$ rz deploy.conf
[hadoop@hd-node1 tools]$ rz deploy.sh
[hadoop@hd-node1 tools]$ rz runRemoteCmd.sh
[hadoop@hd-node1 tools]$ ls
deploy.conf deploy.sh runRemoteCmd.sh
先给脚本增加执行权限,
[hadoop@hd-node1 tools]$ chmod u+x deploy.sh
[hadoop@hd-node1 tools]$ chmod u+x runRemoteCmd.sh
同时我们需要将 /home/hadoop/tools 目录配置到 PATH 环境变量中,方便全局调用。
[hadoop@hd-node1 tools]$ su root
Password:
[root@hd-node1 tools]# vim /etc/profile
export PATH=$PATH:/home/hadoop/tools
[root@hd-node1 tools]# logout
[hadoop@hd-node1 tools]$ source /etc/profile
尝试使用脚本 runRemoteCmd.sh "mkdir -p /home/hadoop/app" all 在所有节点上创建规划的包安装目录。
deploy.conf
配置说明:比如在执行 runRemoteCmd.sh 脚本的时候,最后一个参数为 all,则代表在所有节点执行;如果是 slave,则在 hd-node2、hd-node3、hd-node4 和 hd-node5 执行命令,以此类推。
hd-node1,all,namenode,zookeeper,resourcemanager,
hd-node2,all,slave,namenode,zookeeper,resourcemanager,
hd-node3,all,slave,datanode,zookeeper,
hd-node4,all,slave,datanode,zookeeper,
hd-node5,all,slave,datanode,zookeeper,
deploy sh
分发文件脚本,用法:deploy.sh 源文件(夹) 目标文件(夹) 主机分类,最后的主机分类参数见上面说明。
#!/bin/bash
#set -x
if [ $# -lt 3 ]
then
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag"
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile"
exit
fi
src=$1
dest=$2
tag=$3
if [ 'a'$4'a' == 'aa' ]
then
confFile=/home/hadoop/tools/deploy.conf
else
confFile=$4
fi
if [ -f $confFile ]
then
if [ -f $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp $src $server":"${dest}
done
elif [ -d $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp -r $src $server":"${dest}
done
else
echo "Error: No source file exist"
fi
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
runRemoteCmd sh
用法:runRemoteCmd.sh "命令" 主机分类。
#!/bin/bash
#set -x
if [ $# -lt 2 ]
then
echo "Usage: ./runRemoteCmd.sh Command MachineTag"
echo "Usage: ./runRemoteCmd.sh Command MachineTag confFile"
exit
fi
cmd=$1
tag=$2
if [ 'a'$3'a' == 'aa' ]
then
confFile=/home/hadoop/tools/deploy.conf
else
confFile=$3
fi
if [ -f $confFile ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
echo "*******************$server***************************"
ssh $server "source /etc/profile; $cmd"
done
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
以上三个文件,方便我们搭建 hadoop 分布式集群。具体如何使用看后面如何操作。
jdk 安装
将本地下载好的 jdk-8u112-linux-x64.tar.gz,上传至 hd-node1 节点下的 /home/hadoop/app 目录。
[root@hd-node1 tools]# su hadoop
[hadoop@hd-node1 tools]$ cd /home/hadoop/app/
[hadoop@hd-node1 app]$ rz // 选择本地的下载好的 jdk-8u112-linux-x64.tar.gz
[hadoop@hd-node1 app]$ ls
jdk-8u112-linux-x64.tar.gz
[hadoop@hd-node1 app]$ tar -zxvf jdk-8u112-linux-x64.tar.gz // 解压
[hadoop@hd-node1 app]$ ls
jdk1.8.0_112 jdk-8u112-linux-x64.tar.gz
[hadoop@hd-node1 app]$ rm -f jdk-8u112-linux-x64.tar.gz // 删除安装包
添加 jdk 环境变量。
[hadoop@hd-node1 app]$ su root
Password:
[root@hd-node1 app]# vim /etc/profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_112
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
[root@hd-node1 app]# logout
[hadoop@hd-node1 app]$ source /etc/profile // 使配置文件生效
查看 jdk 是否安装成功。
[hadoop@hd-node1 app]$ java -version
java version "1.8.0_112"
Java(TM) SE Runtime Environment (build 1.8.0_112-b15)
Java HotSpot(TM) 64-Bit Server VM (build 25.112-b15, mixed mode)
[hadoop@hd-node1 app]$
出现以上结果就说明 hd-node1 节点上的 jdk 安装成功。然后将 hd-node1 下的 jdk 安装包复制到其他节点上。
[hadoop@hd-node1 app]$ deploy.sh jdk1.8.0_112 /home/hadoop/app/ slave
hd-node2,hd-node3,hd-node4,hd-node5 节点重复 hd-node1 节点上的 jdk 配置环境变量即可。
Zookeeper 安装
将本地下载好的 zookeeper-3.4.10.tar.gz 安装包,上传至 hd-node1 节点下的 /home/hadoop/app 目录下。
[hadoop@hd-node1 app]$ rz // 选择本地下载好的 zookeeper-3.4.10.tar.gz
[hadoop@hd-node1 app]$ ls
jdk1.8.0_112 zookeeper-3.4.10.tar.gz
[hadoop@hd-node1 app]$ tar -zxvf zookeeper-3.4.10.tar.gz // 解压
[hadoop@hd-node1 app]$ ls
jdk1.8.0_112 zookeeper-3.4.10.tar.gz zookeeper-3.4.10
[hadoop@hd-node1 app]$ rm -f zookeeper-3.4.10.tar.gz // 删除 zookeeper-3.4.10.tar.gz 安装包
[hadoop@hd-node1 app]$ mv zookeeper-3.4.10 zookeeper // 重命名
修改 Zookeeper 中的配置文件。
[hadoop@hd-node1 app]$ cd /home/hadoop/app/zookeeper/conf/
[hadoop@hd-node1 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[hadoop@hd-node1 conf]$ cp zoo_sample.cfg zoo.cfg // 复制一个zoo.cfg文件
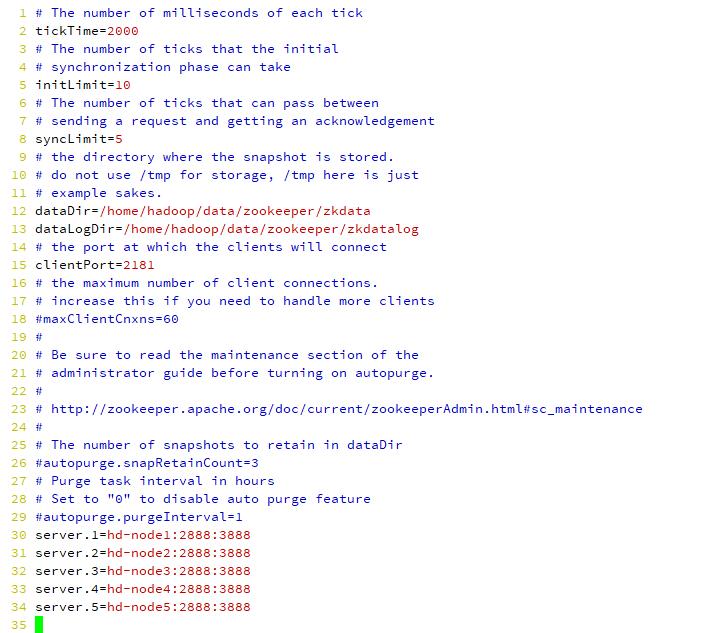
[hadoop@hd-node1 conf]$ vi zoo.cfg
dataDir=/home/hadoop/data/zookeeper/zkdata // 数据文件目录
dataLogDir=/home/hadoop/data/zookeeper/zkdatalog // 日志目录
# the port at which the clients will connect
clientPort=2181 // 默认端口号
# server.服务编号=主机名称:Zookeeper不同节点之间同步和通信的端口:选举端口(选举leader)
server.1=hd-node1:2888:3888
server.2=hd-node2:2888:3888
server.3=hd-node3:2888:3888
server.4=hd-node4:2888:3888
server.5=hd-node5:2888:3888
通过远程命令 deploy.sh 将 Zookeeper 安装目录拷贝到其他节点上面:
[hadoop@hd-node1 app]$ deploy.sh zookeeper /home/hadoop/app slave
通过远程命令 runRemoteCmd.sh 在所有的节点上面创建目录:
[hadoop@hd-node1 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdata" all // 创建数据目录
[hadoop@hd-node1 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdatalog" all // 创建日志目录
然后分别在 hd-node1,hd-node2,hd-node3,hd-node4,hd-node5 上面,进入 zkdata 目录下,创建文件 myid,里面的内容分别填充为:1、2、3、4、5,这里我们以 hd-node1 为例。
[hadoop@hd-node1 app]$ cd /home/hadoop/data/zookeeper/zkdata
[hadoop@hd-node1 zkdata]$ vim myid // 输入数字 1
1
配置 Zookeeper 环境变量:
[hadoop@hd-node1 zkdata]$ su root
Password:
[root@hd-node1 zkdata]# vim /etc/profile
# zookeeper
export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@hd-node1 zkdata]# logout
[hadoop@hd-node1 zkdata]$ source /etc/profile // 使配置文件生效
测试一下 zookeeper 安装,先启动所有节点上的 zookeeper 服务,使用 jps 查看服务进程,然后再关闭服务。
[hadoop@hd-node1 ~]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
*******************hd-node1***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
*******************hd-node2***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
*******************hd-node3***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
*******************hd-node4***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
*******************hd-node5***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hd-node1 ~]$
[hadoop@hd-node1 ~]$
[hadoop@hd-node1 ~]$ runRemoteCmd.sh "jps" all
*******************hd-node1***************************
44333 QuorumPeerMain
44445 Jps
*******************hd-node2***************************
47792 QuorumPeerMain
47890 Jps
*******************hd-node3***************************
41219 Jps
41111 QuorumPeerMain
*******************hd-node4***************************
16964 QuorumPeerMain
17064 Jps
*******************hd-node5***************************
14546 Jps
14454 QuorumPeerMain
[hadoop@hd-node1 ~]$
[hadoop@hd-node1 ~]$
[hadoop@hd-node1 ~]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh stop" zookeeper
*******************hd-node1***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
*******************hd-node2***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
*******************hd-node3***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
*******************hd-node4***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
*******************hd-node5***************************
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
[hadoop@hd-node1 ~]$
hadoop 集群环境搭建
将下载好的 hadoop-2.6.0-cdh5.10.0.tar 安装包,上传至 hd-node1 节点下的 /home/hadoop/app 目录下。
[hadoop@hd-node1 app]$ rz // 将本地的 hadoop-2.6.0-cdh5.10.0.tar 安装包上传至当前目录
[hadoop@hd-node1 app]$ ls
hadoop-2.6.0-cdh5.10.0.tar jdk1.8.0_112 zookeeper
[hadoop@hd-node1 app]$ tar zxvf hadoop-2.6.0.tar.gz //解压
[hadoop@hd-node1 app]$ ls
hadoop-2.6.0-cdh5.10.0 hadoop-2.6.0-cdh5.10.0.tar jdk1.8.0_112 zookeeper
[hadoop@hd-node1 app]$ rm -f hadoop-2.6.0-cdh5.10.0.tar //删除安装包
[hadoop@hd-node1 app]$ mv hadoop-2.6.0-cdh5.10.0 hadoop //重命名
切换到 /home/hadoop/app/hadoop/etc/hadoop/ 目录下,修改配置文件。
[hadoop@hd-node1 app]$ cd /home/hadoop/app/hadoop/etc/hadoop/
配置 HDFS
配置 hadoop-env.sh。
[hadoop@hd-node1 hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_112
配置 core-site.xml。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
<!-- 这里的值指的是默认的 HDFS 路径 ,取名为 cluster1 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
<!-- hadoop 的临时目录,如果需要配置多个目录,需要逗号隔开,data 目录需要我们自己创建 -->
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hd-node1:2181,hd-node2:2181,hd-node3:2181,hd-node4:2181,hd-node5:2181</value>
<!-- 配置 Zookeeper 管理 HDFS -->
</property>
</configuration>
配置 hdfs-site.xml。
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
<!-- 我们有 3 个 datanode, 数据块副本数为3 -->
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 权限默认配置为 false -->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
<!-- 命名空间,它的值与 fs.defaultFS 的值要对应,namenode 高可用之后有两个 namenode,cluster1 是对外提供的统一入口 -->
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>hd-node1,hd-node2</value>
<!-- 指定 nameService 是 cluster1 时的 nameNode 有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可 -->
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.hd-node1</name>
<value>hd-node1:9000</value>
<!-- hd-node1 rpc 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.cluster1.hd-node1</name>
<value>hd-node1:50070</value>
<!-- hd-node1 http 地址 -->
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.hd-node2</name>
<value>hd-node2:9000</value>
<!-- hd-node2 rpc 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.cluster1.hd-node2</name>
<value>hd-node2:50070</value>
<!-- hd-node2 http 地址 -->
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<!-- 启动故障自动恢复 -->
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hd-node1:8485;hd-node2:8485;hd-node3:8485;hd-node4:8485;hd-node5:8485/cluster1</value>
<!-- 指定 journal -->
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<!-- 指定 cluster1 出故障时,哪个实现类负责执行故障切换 -->
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata/jn</value>
<!-- 指定 JournalNode 集群在对 nameNode 的目录进行共享时,自己存储数据的磁盘路径 -->
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
<!-- 脑裂默认配置 -->
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>
配置 slave。
[hadoop@hd-node1 hadoop]$ vim slaves
hd-node3
hd-node4
hd-node5
YARN 安装配置
配置 mapred-site.xml。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<!-- 指定运行 mapreduce 的环境是 Yarn,与 hadoop1 不同的地方 -->
</property>
</configuration>
配置 yarn-site.xml。
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
<!-- 超时的周期 -->
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<!-- 打开高可用 -->
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
<!-- 启动故障自动恢复 -->
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
<!-- failover使用内部的选举算法 -->
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
<!-- 给 yarn cluster 取个名字 yarn-rm-cluster -->
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<!-- 给 ResourceManager 取个名字 rm1,rm2 -->
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hd-node1</value>
<!-- 配置 ResourceManager rm1 hostname -->
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hd-node2</value>
<!-- 配置 ResourceManager rm2 hostname -->
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<!-- 启用resourcemanager 自动恢复 -->
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>hd-node1:2181,hd-node2:2181,hd-node3:2181,hd-node4:2181,hd-node5:2181</value>
<!-- 配置Zookeeper地址 -->
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hd-node1:2181,hd-node2:2181,hd-node3:2181,hd-node4:2181,hd-node5:2181</value>
<!-- 配置Zookeeper地址 -->
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hd-node1:8032</value>
<!-- rm1 端口号 -->
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hd-node1:8034</value>
<!-- rm1调度器的端口号 -->
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hd-node1:8088</value>
<!-- rm1 webapp端口号 -->
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hd-node2:8032</value>
<!-- rm2端口号 -->
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hd-node2:8034</value>
<!-- rm2调度器的端口号 -->
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hd-node2:8088</value>
<!-- rm2 webapp端口号 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<!-- 执行 MapReduce 需要配置的 shuffle 过程 -->
</property>
</configuration>
向所有节点分发 hadoop 安装包。
[hadoop@hd-node1 app]$ deploy.sh hadoop /home/hadoop/app/ slave
向集群其它节点分发安装包,需要一点时间。
启动集群
- 启动所有 Zookeeper
[hadoop@hd-node1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
- 启动所有节点的 journalnode
[hadoop@hd-node1 ~]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode" all
*******************hd-node1***************************
starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node1.out
*******************hd-node2***************************
starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node2.out
*******************hd-node3***************************
starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node3.out
*******************hd-node4***************************
starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node4.out
*******************hd-node5***************************
starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node5.out
[hadoop@hd-node1 ~]$
- 主节点执行格式化
NameNode hd-node1 上格式化操作。
[hadoop@hd-node1 hadoop]$ bin/hdfs namenode -format // namenode 格式化
[hadoop@hd-node1 hadoop]$ bin/hdfs zkfc -formatZK // 格式化高可用
[hadoop@hd-node1 hadoop]$ bin/hdfs namenode // 启动 namenode
- 备节点执行
在 hd-node2 上同步主节点的元数据。
[hadoop@hd-node2 zkdata]$ hdfs namenode -bootstrapStandby
18/12/10 23:04:57 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = hadoop
STARTUP_MSG: host = hd-node2/192.190.20.14
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 2.6.0-cdh5.10.0
STARTUP_MSG: classpath = ...
...
STARTUP_MSG: build = http://github.com/cloudera/hadoop -r 307b3de961d083f6e8ee80ddba589f22cacd3662; compiled by 'jenkins' on 2017-01-20T20:09Z
STARTUP_MSG: java = 1.8.0_112
************************************************************/
18/12/10 23:04:57 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
18/12/10 23:04:57 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
18/12/10 23:04:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
=====================================================
About to bootstrap Standby ID hd-node2 from:
Nameservice ID: cluster1
Other Namenode ID: hd-node1
Other NN's HTTP address: http://hd-node1:50070
Other NN's IPC address: hd-node1/192.190.20.13:9000
Namespace ID: 1340338484
Block pool ID: BP-1704877251-192.190.20.13-1544454003304
Cluster ID: CID-ea278424-1c90-4594-980c-5dcd95edda74
Layout version: -60
isUpgradeFinalized: true
=====================================================
18/12/10 23:04:58 INFO common.Storage: Storage directory /home/hadoop/data/tmp/dfs/name has been successfully formatted.
18/12/10 23:04:58 INFO namenode.FSEditLog: Edit logging is async:false
18/12/10 23:04:59 INFO namenode.TransferFsImage: Opening connection to http://hd-node1:50070/imagetransfer?getimage=1&txid=0&storageInfo=-60:1340338484:0:CID-ea278424-1c90-4594-980c-5dcd95edda74&bootstrapstandby=true
18/12/10 23:04:59 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds
18/12/10 23:04:59 INFO namenode.TransferFsImage: Transfer took 0.01s at 0.00 KB/s
18/12/10 23:04:59 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 323 bytes.
18/12/10 23:04:59 INFO util.ExitUtil: Exiting with status 0
18/12/10 23:04:59 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hd-node2/192.190.20.14
************************************************************/
[hadoop@hd-node2 zkdata]$
- 停掉 hadoop,在 hd-node1 按下
ctrl+c结束 namenode,
^C18/12/10 23:12:00 ERROR namenode.NameNode: RECEIVED SIGNAL 2: SIGINT
18/12/10 23:12:00 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hd-node1/192.190.20.13
************************************************************/
[hadoop@hd-node1 ~]$
然后停掉各节点的 journalnode。
[hadoop@hd-node1 ~]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode" all
*******************hd-node1***************************
stopping journalnode
*******************hd-node2***************************
stopping journalnode
*******************hd-node3***************************
stopping journalnode
*******************hd-node4***************************
stopping journalnode
*******************hd-node5***************************
stopping journalnode
[hadoop@hd-node1 ~]$
- 一键启动 hdfs 相关进程
[hadoop@hd-node1 hadoop]$ ./sbin/start-dfs.sh
18/12/10 23:14:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hd-node2 hd-node1]
hd-node1: starting namenode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-namenode-hd-node1.out
hd-node2: starting namenode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-namenode-hd-node2.out
hd-node3: starting datanode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-datanode-hd-node3.out
hd-node4: starting datanode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-datanode-hd-node4.out
hd-node5: starting datanode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-datanode-hd-node5.out
Starting journal nodes [hd-node1 hd-node2 hd-node3 hd-node4 hd-node5]
hd-node3: starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node3.out
hd-node1: starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node1.out
hd-node2: starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node2.out
hd-node4: starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node4.out
hd-node5: starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-hd-node5.out
18/12/10 23:14:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting ZK Failover Controllers on NN hosts [hd-node2 hd-node1]
hd-node1: starting zkfc, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-zkfc-hd-node1.out
hd-node2: starting zkfc, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-zkfc-hd-node2.out
[hadoop@hd-node1 hadoop]$
- 在 hd-node1 节点上执行。
[hadoop@hd-node1 hadoop]$ ./sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/app/hadoop/logs/yarn-hadoop-resourcemanager-hd-node1.out
hd-node3: starting nodemanager, logging to /home/hadoop/app/hadoop/logs/yarn-hadoop-nodemanager-hd-node3.out
hd-node4: starting nodemanager, logging to /home/hadoop/app/hadoop/logs/yarn-hadoop-nodemanager-hd-node4.out
hd-node5: starting nodemanager, logging to /home/hadoop/app/hadoop/logs/yarn-hadoop-nodemanager-hd-node5.out
[hadoop@hd-node1 hadoop]$
- 在 hd-node2 节点上面执行。
[hadoop@hd-node2 hadoop]$ ./sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/app/hadoop/logs/yarn-hadoop-resourcemanager-hd-node2.out
[hadoop@hd-node2 hadoop]$
- 验证 namenode:
http://hd-node1:50070
http://hd-node2:50070
- 验证 yarn:
http://hd-node1:8088
http://hd-node2:8088