hbase 基本概念、快速安装上手和 hbase shell 常用命令用法
HBase 概念
简介
HBase 是一个分布式的、面向列的开源数据库,源于 google 的一篇论文 《bigtable:一个结构化数据的分布式存储系统》。HBase 是 Google Bigtable 的开源实现,它利用 Hadoop HDFS 作为其文件存储系统,利用 Hadoop MapReduce 来处理 HBase 中的海量数据,利用 Zookeeper 作为协同服务。
HBase 的表结构
HBase 以表的形式存储数据。表有行和列组成。列划分为若干个列族/列簇(column family)。
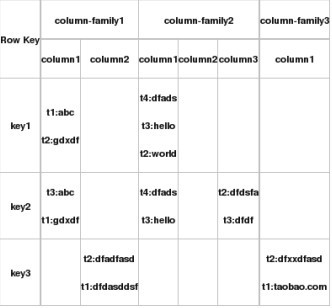
如上图所示,key1, key2, key3 是三条记录的唯一的 row key 值,column-family1, column-family2, column-family3 是三个列族,每个列族下又包括几列。比如 column-family1 这个列族下包括两列,名字是 column1 和 column2,t1:abc, t2:gdxdf 是由 row key1 和 column-family1-column1 唯一确定的一个单元 cell。这个 cell 中有两个数据,abc 和 gdxdf。两个值的时间戳不一样,分别是 t1, t2, HBase 会返回最新时间的值给请求者。
名词术语
这些名词的具体含义如下:
Row Key
与 nosql 数据库一样,row key 是用来检索记录的主键。访问 hbase table 中的行,只有三种方式:
- 通过单个 row key 访问
- 通过 row key 的 range
- 全表扫描
Row key 行键 (Row key) 可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在 HBase 内部,row key 保存为字节数组。
存储时,数据按照 Row key 的字典序 (byte order) 排序存储。设计 key 时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
注意,字典序对 int 排序的结果是:
1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99
要保持整形的自然序,行键必须用 0 作左填充。
行的一次读写是原子操作 (不论一次读写多少列)。这个设计决策能够使用户很容易的理解程序在对同一个行进行并发更新操作时的行为。
列族 column family
HBase 表中的每个列,都归属与某个列族。列族是表的 schema 的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history,courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。
单元 Cell
HBase 中通过 row 和 columns 确定的为一个存贮单元称为 cell。
由 {row key, column( =<family> + <label>), version} 唯一确定的单元。
cell 中的数据是没有类型的,全部是字节码形式存贮。
时间戳 timestamp
每个 cell 都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64 位整型。时间戳可以由 HBase (在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell 中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBase 提供了两种数据版本回收方式。一是保存数据的最后 n 个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
HBase 快速安装
到 官网下载 HBase 最新或合适的版本,放到合适的目录,比如 /usr/local 或 /opt 之后解压。
tar -zxvf hbase-x.y.z tar.gz
进入解压后的目录,以本地单机模式启动 HBase。
./bin/start-hbase.sh
HBase shell
HBase 提供了一个 shell 的终端给用户交互,使用 hbase shell 启动交互终端。
[Hadoop@Hadoop0 hbase-1.2.6]$ ./bin/hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/Hadoop/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/Hadoop/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
hbase(main):001:0>
输入 help 可以查看命令列表和简易帮助,通过执行 help get 可以看到具体命令的帮助信息。
hbase(main):001:0> help
HBase Shell, version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: status, table_help, version, whoami
Group name: ddl
Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
Group name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_rs, flush, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, trace, unassign, wal_roll, zk_dump
Group name: replication
Commands: add_peer, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs
Group name: snapshots
Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot
Group name: configuration
Commands: update_all_config, update_config
Group name: quotas
Commands: list_quotas, set_quota
Group name: security
Commands: grant, list_security_capabilities, revoke, user_permission
Group name: procedures
Commands: abort_procedure, list_procedures
Group name: visibility labels
Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility
SHELL USAGE:
Quote all names in HBase Shell such as table and column names. Commas delimit
command parameters. Type <RETURN> after entering a command to run it.
Dictionaries of configuration used in the creation and alteration of tables are
Ruby Hashes. They look like this:
{'key1' => 'value1', 'key2' => 'value2', ...}
and are opened and closed with curley-braces. Key/values are delimited by the
'=>' character combination. Usually keys are predefined constants such as
NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type
'Object.constants' to see a (messy) list of all constants in the environment.
If you are using binary keys or values and need to enter them in the shell, use
double-quote'd hexadecimal representation. For example:
hbase> get 't1', "key\x03\x3f\xcd"
hbase> get 't1', "key\003\023\011"
hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"
The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added.
For more on the HBase Shell, see http://hbase.apache.org/book.html
hbase(main):002:0>
可以看到一些命令分组:
| Group name | Commands |
|---|---|
| general | status, table_help, version, whoami |
| ddl | alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, locate_region, show_filters |
| namespace | alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables |
| dml | append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve |
| tools | assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_rs, flush, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, trace, unassign, wal_roll, zk_dump |
| replication | add_peer, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs |
| snapshots | clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot |
| configuration | update_all_config, update_config |
| quotas | list_quotas, set_quota |
| security | grant, list_security_capabilities, revoke, user_permission |
| procedures | abort_procedure, list_procedures |
| visibility labels | add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility |
列出常用的数据操作命令清单如下:
| 操作名称 | 命令表达式 |
|---|---|
| 创建表 | create '表名称', '列名称1', '列名称2', '列名称N' |
| 添加记录 | put '表名称', '行名称', '列名称:', '值' |
| 查看记录 | get '表名称', '行名称' |
| 查看表中的记录总数 | count '表名称' |
| 删除记录 | delete '表名称', '行名称', '列名称' |
| 查看表中所有记录 | scan '表名称' |
| 查看某个表某个列中所有数据 | scan '表名称', ['列名称:'] |
| 删除一张表 | 第一步: disable '表名称' (先要使表处于 disable 状态,才能对表进行删除操作);第二步: drop '表名称' |
| 更新记录 | 就是重写一遍进行覆盖 |
shell 操作
下面按分组对一些常用的 HBase shell 命令做演示。
general 操作
查看 HBase 版本
hbase(main):001:0> version
1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
hbase(main):002:0>
查看 HBase 服务器状态
hbase(main):002:0> status
1 active master, 1 backup masters, 2 servers, 0 dead, 2.0000 average load
hbase(main):003:0>
查看 HBase 当前用户信息
hbase(main):003:0> whoami
Hadoop (auth:SIMPLE)
groups: Hadoop
hbase(main):004:0>
ddl 操作
创建一个表
hbase(main):001:0> create 'table1', 'tab1_id', 'tab1_add', 'tab1_info'
0 row(s) in 1.6390 seconds
=> Hbase::Table - table1
hbase(main):002:0>
列出所有的表
hbase(main):002:0> list
TABLE
janusgraph
janusgraph-socket-credentials
table1
3 row(s) in 0.0310 seconds
=> ["janusgraph", "janusgraph-socket-credentials", "table1"]
hbase(main):003:0>
获得表的描述
hbase(main):003:0> describe 'table1'
Table table1 is ENABLED
table1
COLUMN FAMILIES DESCRIPTION
{NAME => 'tab1_add', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZ
E => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'tab1_id', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE
=> '65536', REPLICATION_SCOPE => '0'}
{NAME => 'tab1_info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSI
ZE => '65536', REPLICATION_SCOPE => '0'}
3 row(s) in 0.1710 seconds
hbase(main):004:0>
删除一个列族
修改表结构,需要先 disable 表,在使用 alter 修改表,修改完成之后在 enable 表。
hbase(main):004:0> disable 'table1'
0 row(s) in 2.2760 seconds
hbase(main):005:0> alter 'table1', {NAME=>'tab1_add', METHOD=>'delete'}
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.9320 seconds
hbase(main):006:0> enable 'table1'
0 row(s) in 1.2510 seconds
hbase(main):007:0>
查看表是否存在
这个命令感觉有 BUG,不管查看哪个表都是 Table does not exist。😓
hbase(main):010:0> exists 'table2'
Table table2 does not exist
0 row(s) in 0.0110 seconds
hbase(main):011:0>
判断表是否为 enable
hbase(main):011:0> is_enabled 'table1'
true
0 row(s) in 0.0160 seconds
hbase(main):012:0>
判断表是否为 disable
hbase(main):012:0> is_disabled 'table1'
false
0 row(s) in 0.0220 seconds
hbase(main):013:0>
删除一个表
删除一个表需要先 diable 表。
hbase(main):013:0> disable 'table1'
0 row(s) in 2.2410 seconds
hbase(main):014:0> drop 'table1'
0 row(s) in 1.2590 seconds
hbase(main):015:0>
dml 等操作看以下示例。
shell 应用示例
以网上的一个学生成绩表的例子来完整演示 HBase shell 的用法。
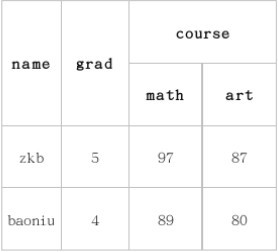
这里 grad 对于表来说是一个列,course 对于表来说是一个列族,这个列族由两个列组成 math 和 art,当然我们可以根据我们的需要在 course 中建立更多的列族,如 computer,physics 等相应的列添加入 course 列族。图中需要注意的是 90 这个值,列族下面的列也是可以没有名字的。
- 建立一个表格
scores具有两个列族grad和courese
hbase(main):001:0> create 'scores', 'grade', 'course'
0 row(s) in 0.4780 seconds
- 查看当前 HBase 中具有哪些表
hbase(main):002:0> list
TABLE
scores
1 row(s) in 0.0270 seconds
- 查看表的构造
hbase(main):004:0> describe 'scores'
DESCRIPTION ENABLED
{NAME => 'scores', FAMILIES => [{NAME => 'course', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', true
COMPRESSION => 'NONE', VERSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'fal
se', BLOCKCACHE => 'true'}, {NAME => 'grade', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', COMPR
ESSION => 'NONE', VERSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false',
BLOCKCACHE => 'true'}]}
1 row(s) in 0.0390 seconds
- 加入一行数据,行名称为 zkb 列族 grad 的列名为 "" 值为 5
hbase(main):006:0> put 'scores', 'zkb', 'grade:', '5'
0 row(s) in 0.0420 seconds
- 给 zkb 这一行的数据的列族 course 添加一列
<math,97>
hbase(main):007:0> put 'scores', 'zkb', 'course:math', '97'
0 row(s) in 0.0270 seconds
- 给 zkb 这一行的数据的列族 course 添加一列
<art,87>
hbase(main):008:0> put 'scores', 'zkb', 'course:art', '87'
0 row(s) in 0.0260 seconds
- 加入一行数据,行名称为
baoniu列族 grad 的列名为 "" 值为 4
hbase(main):009:0> put 'scores', 'baoniu', 'grade:', '4'
0 row(s) in 0.0260 seconds
- 给 baoniu 这一行的数据的列族 course 添加一列
<math,89>
hbase(main):010:0> put 'scores', 'baoniu', 'course:math', '89'
0 row(s) in 0.0270 seconds
- 给 baoniu 这一行的数据的列族 course 添加一列
<art,80>
hbase(main):011:0> put 'scores', 'baoniu', 'course:art', '80'
0 row(s) in 0.0270 seconds
- 查看 scores 表中 zkb 的相关数据
hbase(main):012:0> get 'scores','zkb'
COLUMN CELL
course:art timestamp=1316100110921, value=87
course:math timestamp=1316100025944, value=97
grade: timestamp=1316099975625, value=5
3 row(s) in 0.0480 seconds
- 查看 scores 表中所有数据
注意:scan 命令可以指定 startrow,stoprow 来 scan 多个 row,例如:scan 'user_test',{COLUMNS =>'info:username',LIMIT =>10, STARTROW => 'test',STOPROW=>'test2'}。
hbase(main):013:0> scan 'scores'
ROW COLUMN+CELL
baoniu column=course:art, timestamp=1316100293784, value=80
baoniu column=course:math, timestamp=1316100234410, value=89
baoniu column=grade:, timestamp=1316100178609, value=4
zkb column=course:art, timestamp=1316100110921, value=87
zkb column=course:math, timestamp=1316100025944, value=97
zkb column=grade:, timestamp=1316099975625, value=5
2 row(s) in 0.0470 seconds
- 查看 scores 表中所有数据 courses 列族的所有数据
hbase(main):017:0> scan 'scores',{COLUMNS => 'course'}
ROW COLUMN+CELL
baoniu column=course:art, timestamp=1316100293784, value=80
baoniu column=course:math, timestamp=1316100234410, value=89
zkb column=course:art, timestamp=1316100110921, value=87
zkb column=course:math, timestamp=1316100025944, value=97
2 row(s) in 0.0350 seconds
- 删除 scores 表
hbase(main):024:0> disable 'scores'
0 row(s) in 0.0330 seconds
hbase(main):025:0> drop 'scores'
0 row(s) in 1.0840 seconds
总结
HBase shell 常用的操作命令有 create,describe,disable,drop,list,scan,put,get,delete,deleteall,count,status 等,通过 help 可以看到详细的用法。